Azure Databricks Setup#
This section covers how to install and setup Big Data Toolkit in Azure Databricks.
Create Resource Group#
Go to http://portal.azure.com. Under
Resource Groups. Add a new resource group.
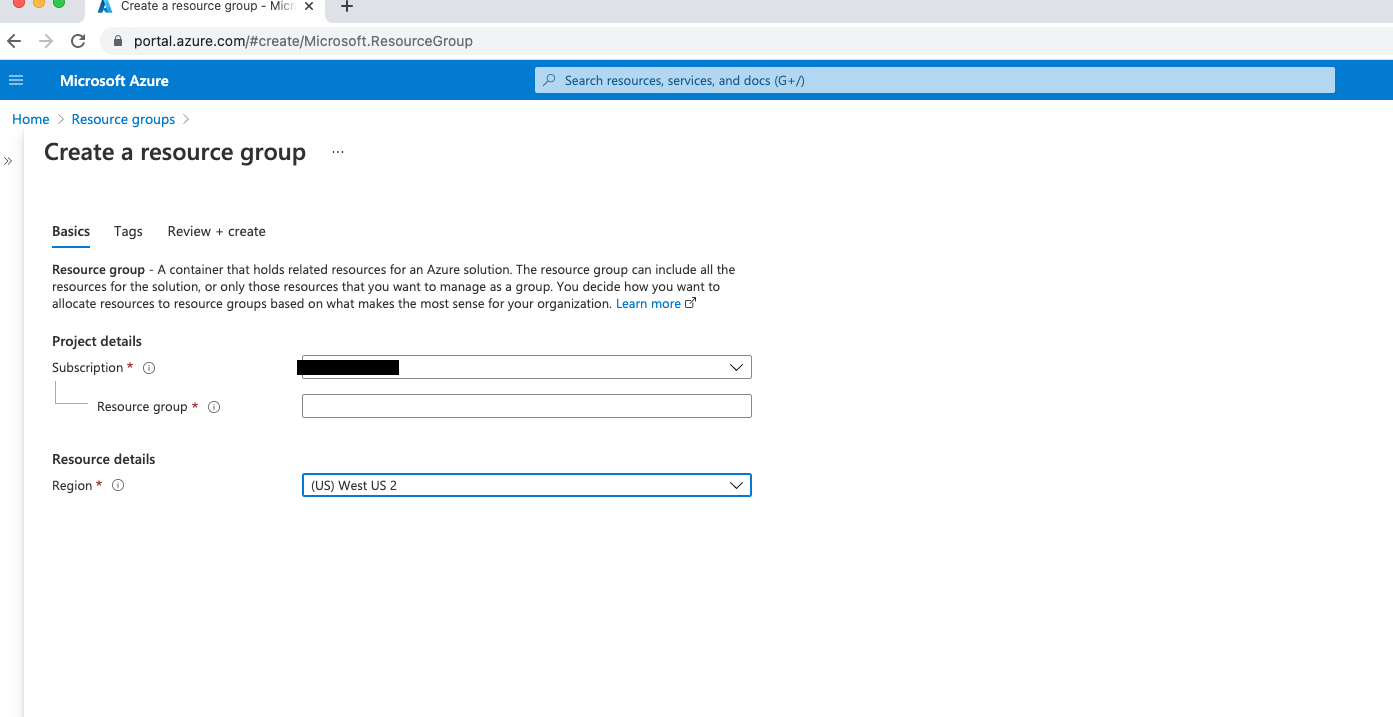
Go to your resource group. Add a storage account in the same region as your resource group.

Create Storage Account#
Search for Storage Account and follow these steps:
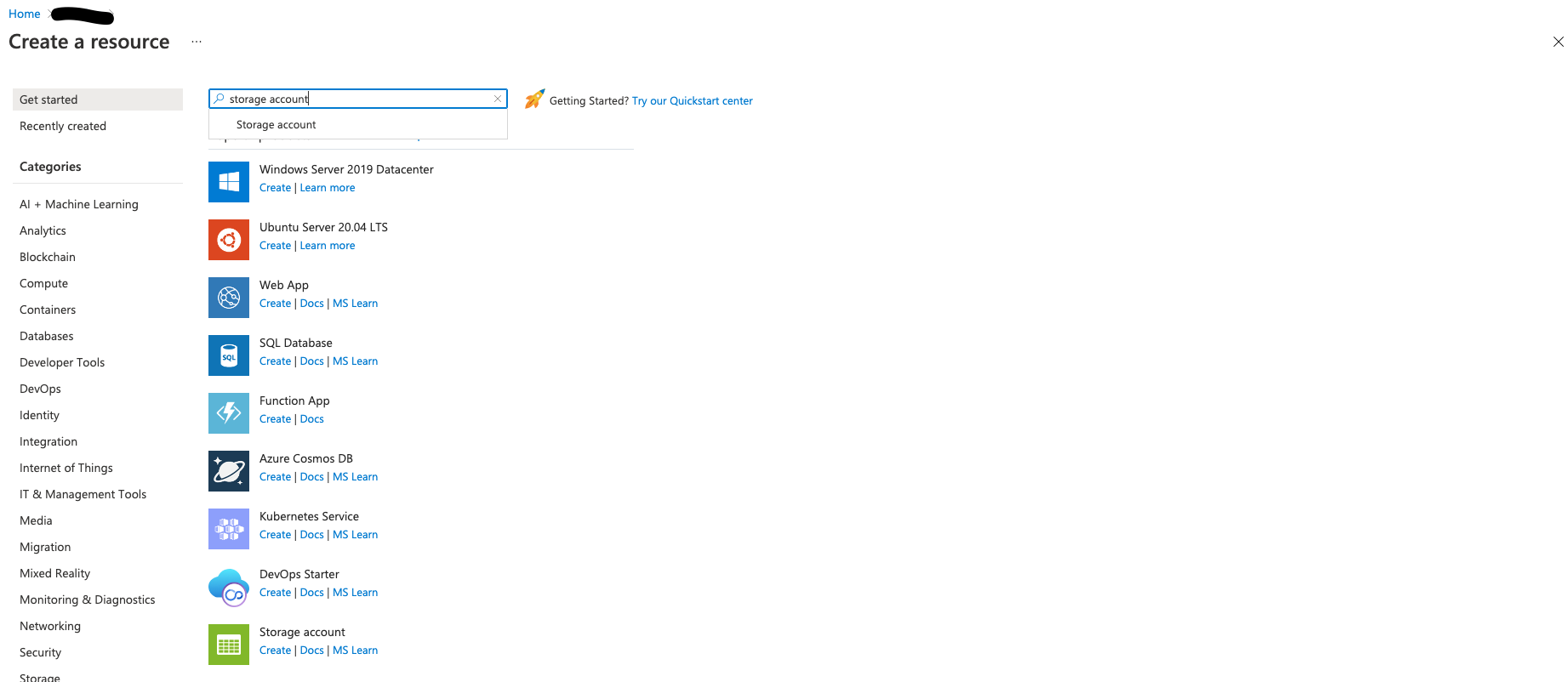
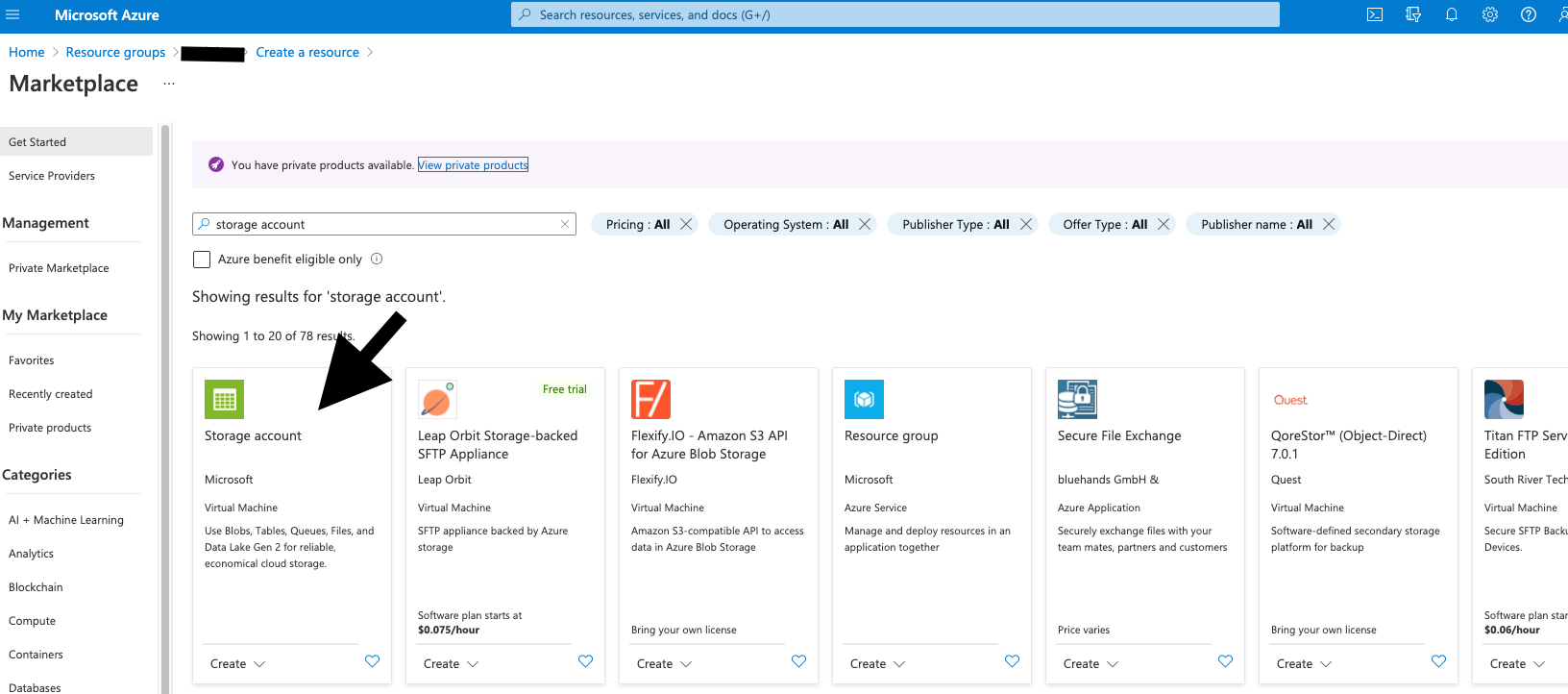
Use the same region, standard performance, and select LRS
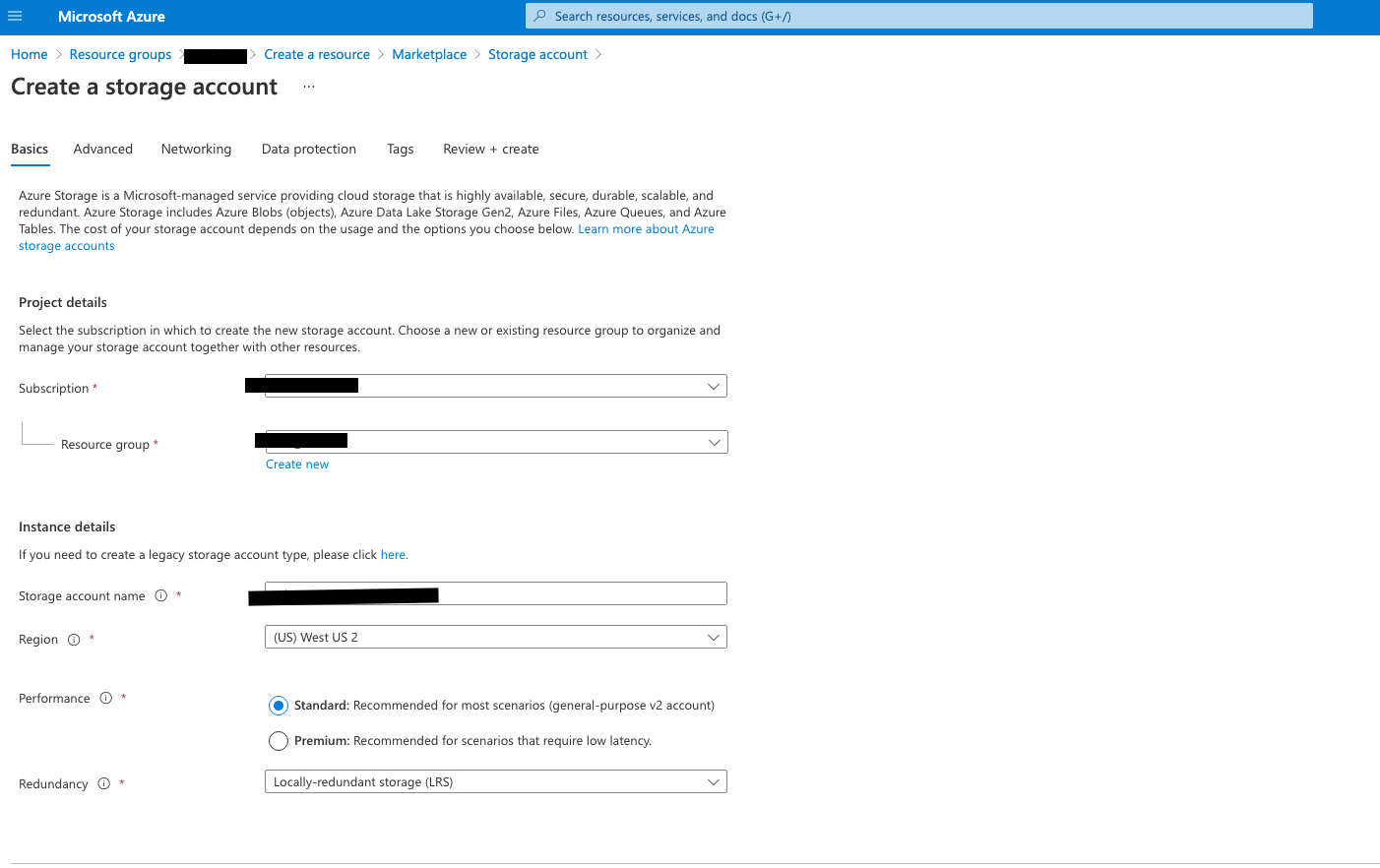
Make sure to enable hierarchical namespace
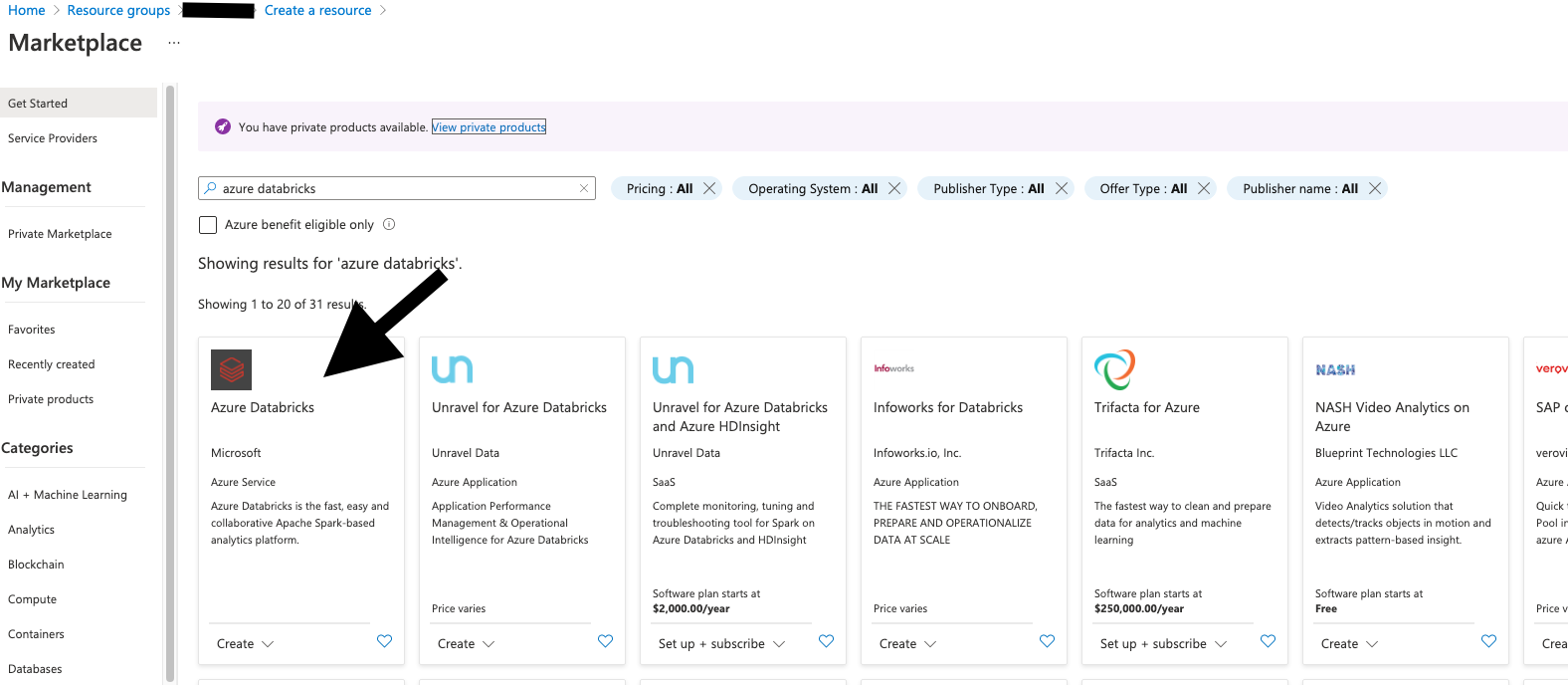
Add Databricks Service to Resource Group#
In your resource group, add
Azure Databricks Service.
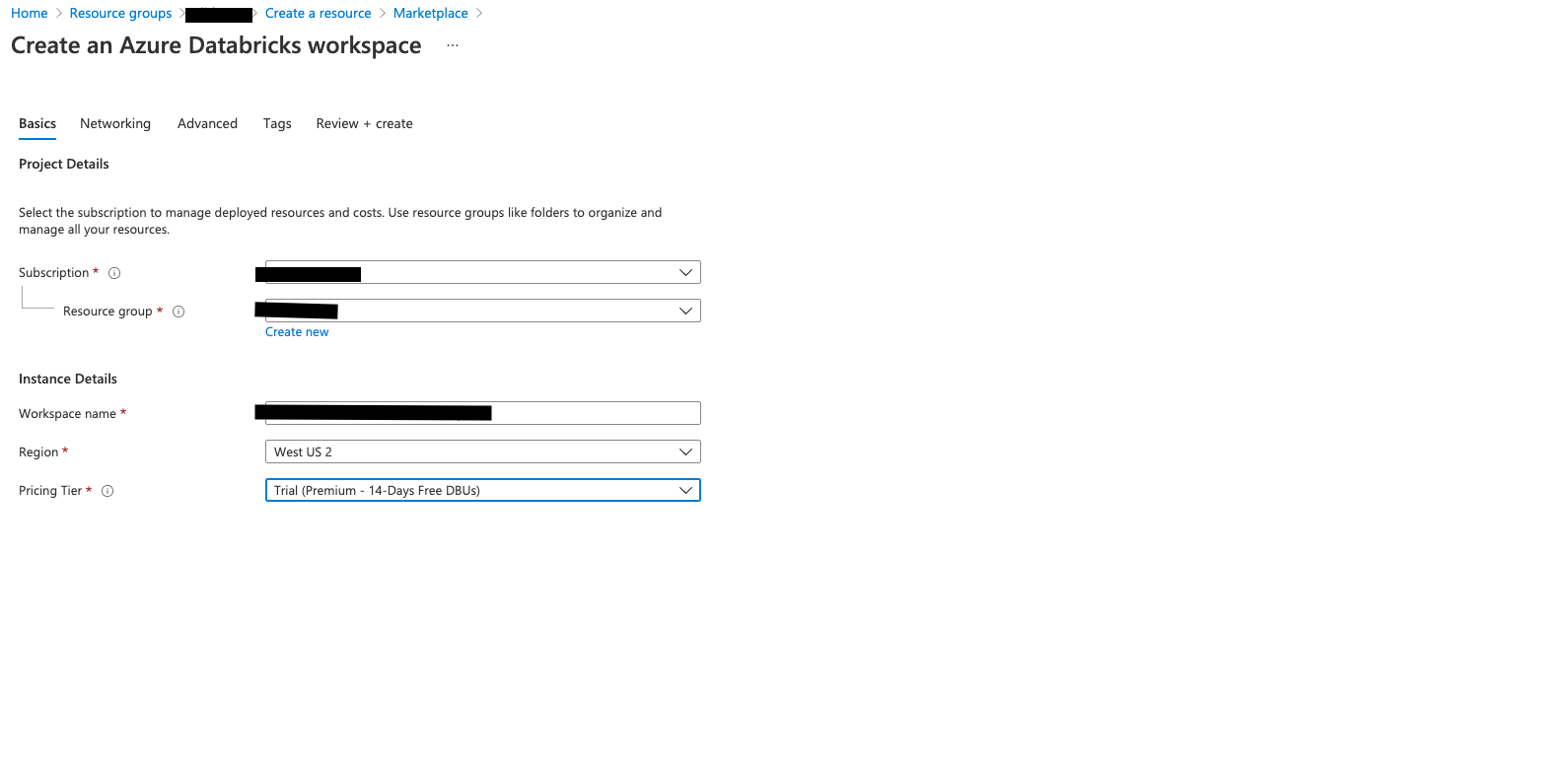
Install & configure Databricks CLI#
Launch Databricks workspace.
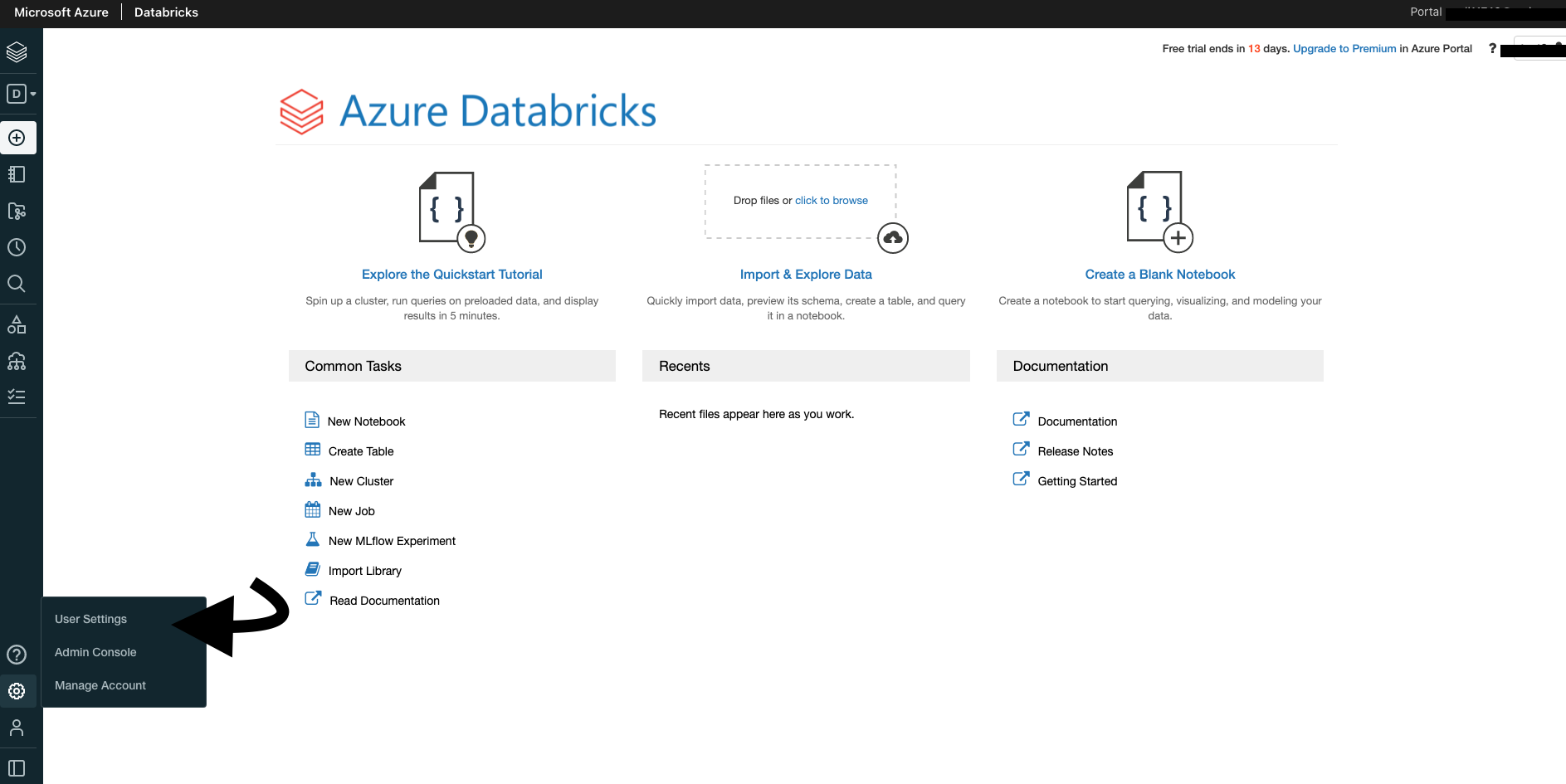
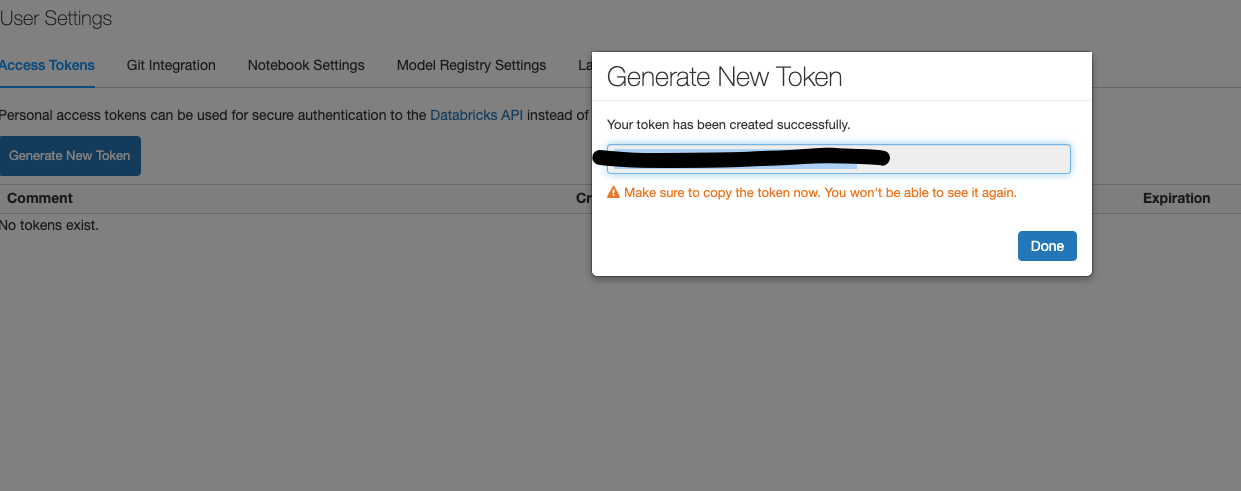
Click on Generate New Token
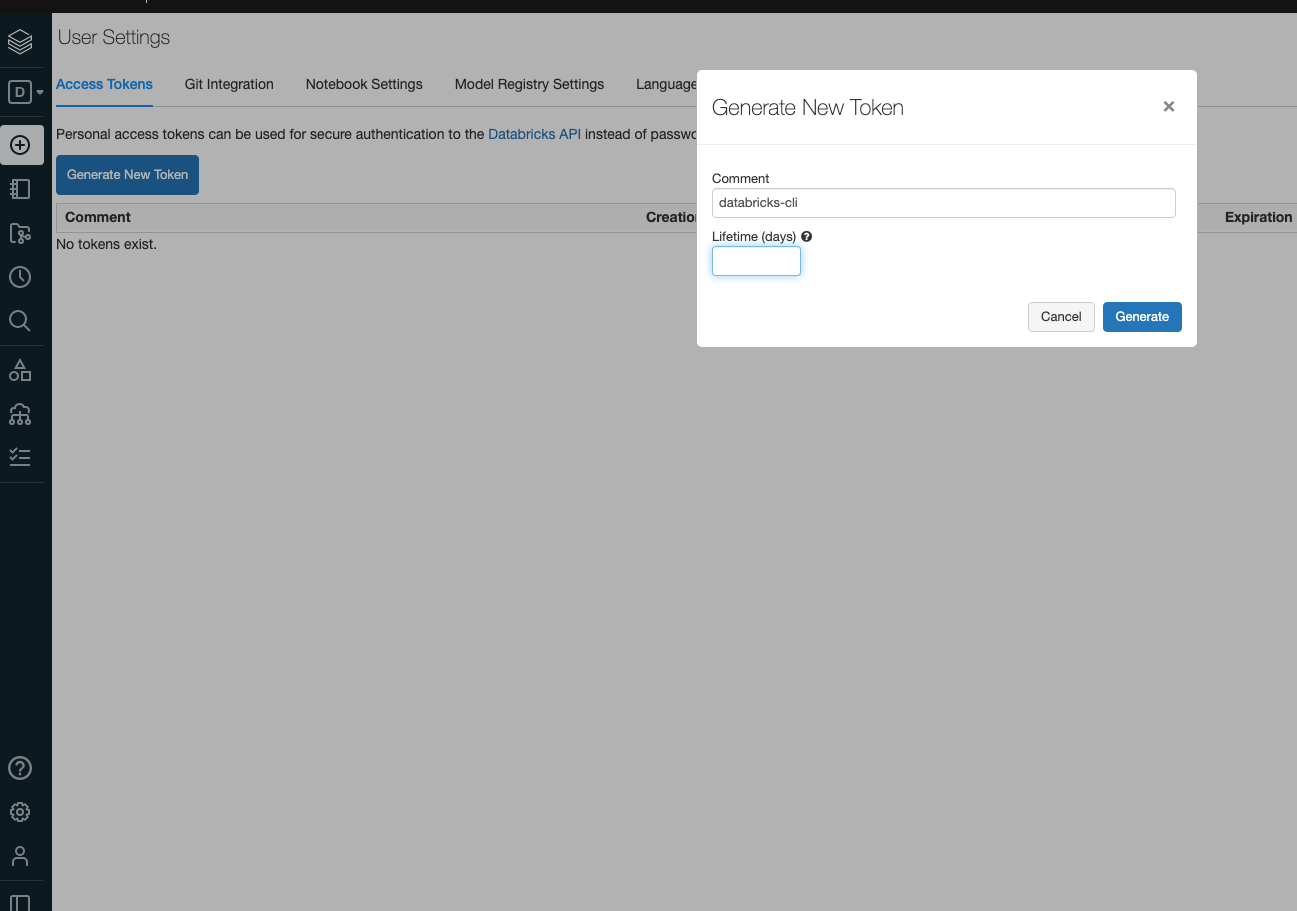
Save the token in a safe place
In your terminal, execute
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh.Execute
export PATH="/root/bin:$PATH"Execute
databricks configureWhen prompted, enter your databricks Host and hit enter. An example value for Databricks Host is
https://westus2.azuredatabricks.net, or your Workspace Instance URLWhen prompted, paste the token for your databricks workspace and hit enter.
Use Principal Key to setup ABFSS#
Setup of a service principal in your Azure subscription is a prerequisite
After this is setup, enter the following in your terminal:
databricks secrets create-scope adls --initial-manage-principal users
databricks secrets put-secret adls credential
A prompt will appear, asking you to enter the value of your credential. Paste the service principal and hit enter.
Add Notebook to Databricks Workspace#
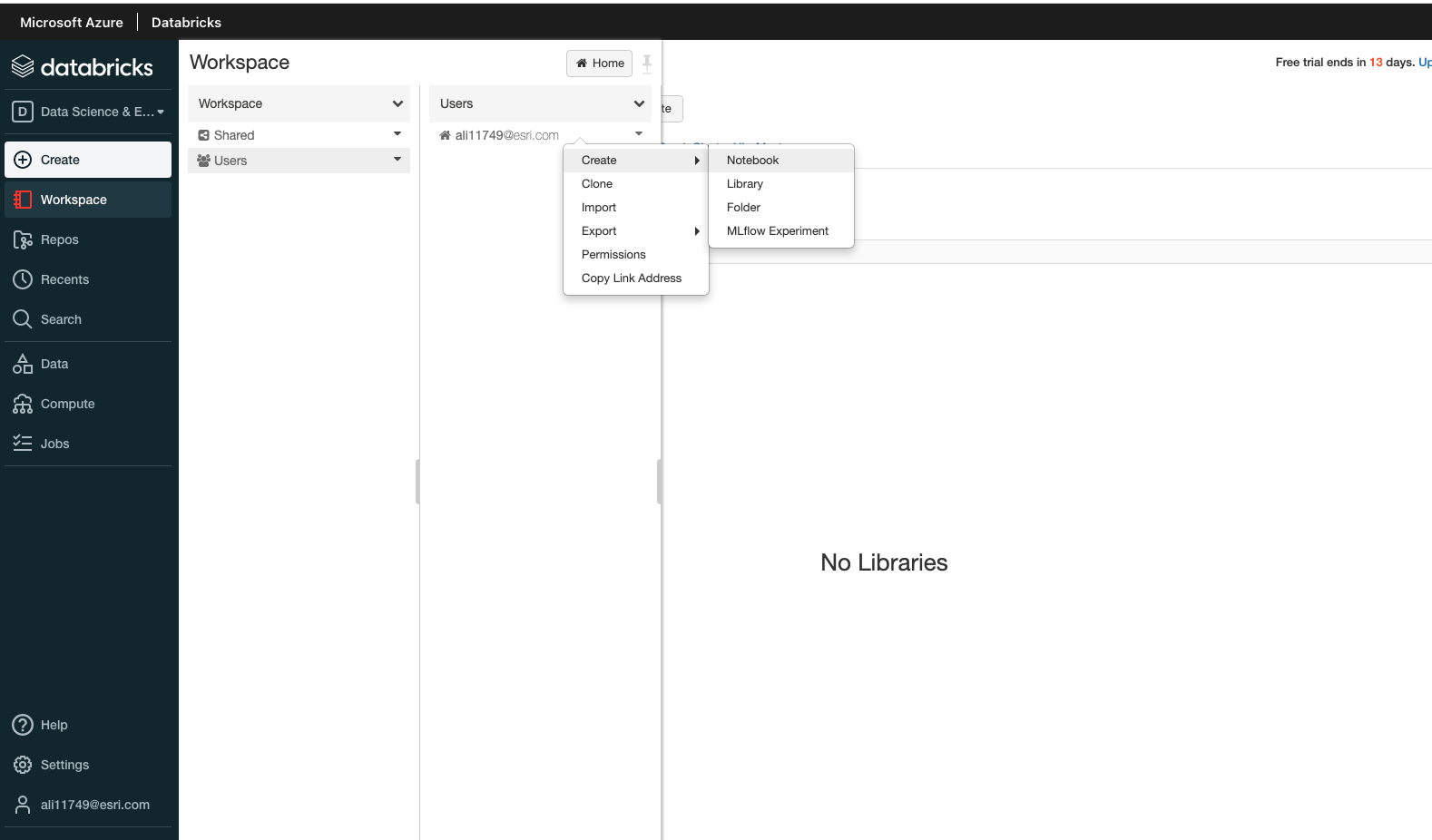
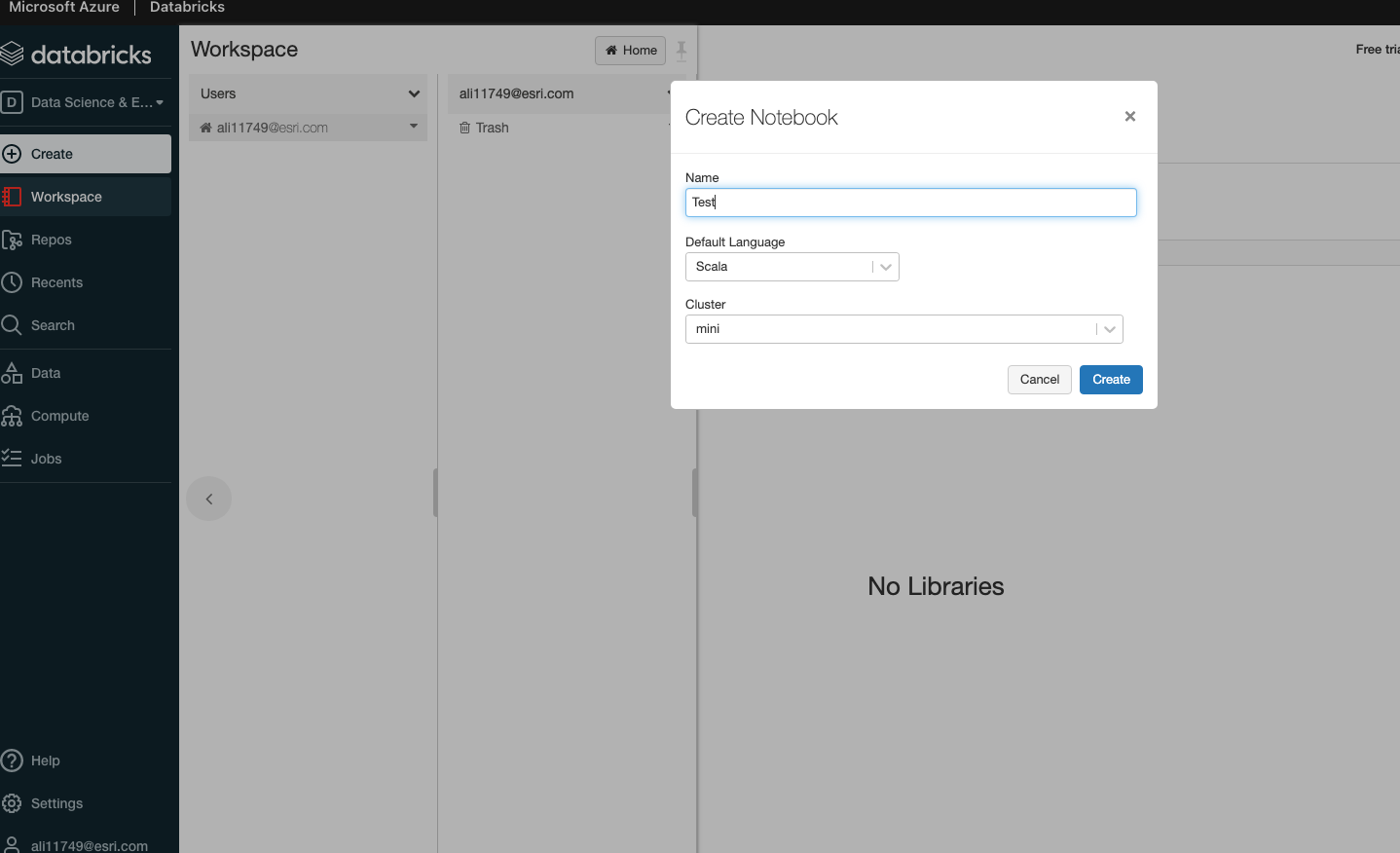
Create a Databricks Cluster#
The Databricks Runtime of the cluster depends on the version of BDT3.
For BDT3 Version 3.0: DBR 10.4 LTS
For BDT3 Version 3.1: DBR 11.x
For BDT3 Version 3.2: DBR 12.2 LTS, DBR 13.3 LTS
For BDT3 Version 3.3: DBR 14.3 LTS
For BDT3 Version 3.4: DBR 14.3 LTS
For BDT3 Version 3.5: DBR 16.4 LTS
Currently, Shared access mode is not supported. A policy must be selected that does not force shared access mode. See the table of Databricks policies and access modes supported by BDT on the System Requirements page for more details.
Install Big Data Toolkit#
The BDT jar and whl files must be installed either from the Databricks Workspace or from Azure Storage.
Upload the jar and whl files to the databricks workspace or to a location in Azure
Go to Cluster Libraries and install the jar and whl from their location in the Workspace or Azure storage
If the Workspace is enabled for Unity Catalog the BDT jar must be installed from a Volume
Upload the jar to a location in Azure Blob, create an external location in the Unity Catalog, and assign users read permissions.
Register the external location as a Volume in the Unity Catalog
In the Catalog tab navigate through the Volume and copy the path to the BDT jar
Go to Cluster Libraries and install the jar from the Volume path
We recommend installing the BDT whl from the Volume as well but Databricks also allows python libraries from the Workspace
It is also recommended to install GeoPandas and its supporting libraries to visualize results in notebooks. Use PyPi in the cluster library installation window to install the following libraries:
geopandas
folium
matplotlib
mapclassify
* pyarrow is also required for GeoPandas visualization but is already pre-installed in databricks
How to access Azure Blob Storage#
There are three supported methods to connect to Azure Data Lake Storage in Databricks:
See Connect to Azure Data Lake Storage Gen2 and Blob Storage for details on how to connect using the various methods. Currently, in order to use Big Data Toolkit in Databricks, these instructions must be modified slightly. See the appropriate sections below for more detail on each connection method.
Access Azure Storage using Azure Service Principal#
To connect to Azure Storage using the Service Principal Key acquired earlier in these instructions, place the following configuration in the spark config of your cluster. Modify <secret-scope> and <service-credential-key> to match the information you configured when setting up ABFSS.
spark.hadoop.fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net OAuth
spark.hadoop.fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
spark.hadoop.fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net <application-id>
spark.hadoop.fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net {{secrets/<secret-scope>/<service-credential-key>}}
spark.hadoop.fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net https://login.microsoftonline.com/<directory-id>/oauth2/token
Access Azure Storage using SAS Token#
To connect to Azure Storage using a SAS Token, first create a SAS token for your storage account. The following properties will need to be enabled to allow the authorization of Databricks:
Once the SAS Token has been created, store it as a Databricks Secret using the following commands.
databricks secrets create-scope --scope adls --initial-manage-principal users
databricks secrets put --scope adls --key SAStoken
Then, place the following into the spark config for the cluster and replace <storage-account> with the name of your storage account.
spark.hadoop.fs.azure.sas.fixed.token.<storage-account>.dfs.core.windows.net {{secrets/adls/SAStoken}}
spark.hadoop.fs.azure.sas.token.provider.type.<storage-account>.dfs.core.windows.net org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider
spark.hadoop.fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net SAS
Access Azure Storage using Account Key#
To connect to Azure Storage using an account key, first view your account access keys. Copy the value for key1 for use as the account key to Azure Storage and Big Data Toolkit and keep it safe for later use.
Store the account key as a Databricks Secret using the following commands.
databricks secrets create-scope --scope adls --initial-manage-principal users
databricks secrets put --scope adls --key accountkey
Then, place the following into the spark config for the cluster and replace <storage-account> with the name of your storage account.
spark.hadoop.fs.azure.account.key.<storage-account>.dfs.core.windows.net {{secrets/adls/accountkey}}
Access Azure Storage using Unity Catalog#
As an administrator, create a managed identity and access connector that provide access to the storage accounts in the Azure portal. The managed identity will be used to access the storage account from Databricks.