AWS Databricks Setup#
This section covers how to install and setup Big Data Toolkit in Databricks in AWS.
Creating an S3 Bucket#
An S3 bucket is required to store the data that BDT will process. Start by following this guide to create an S3 Bucket within AWS.
Creating an S3 Bucket is required to use BDT’s Geoenrichment and Network Analysis functionalities.
Subscribing to Databricks on AWS#
To begin, search for Databricks in AWS Marketplace. Subscribe to the Databricks Data Intelligence Platform.
Deploying Databricks on AWS#
New Databricks Workspaces can be created through Databricks. However, the user creating the workspace must have admin privileges in AWS.
To create a new workspace, log in to databricks and navigate to the workspaces tab of the account console. Select the Create Workspace button in the top right corner.

Select the region of choice and proceed with directions.
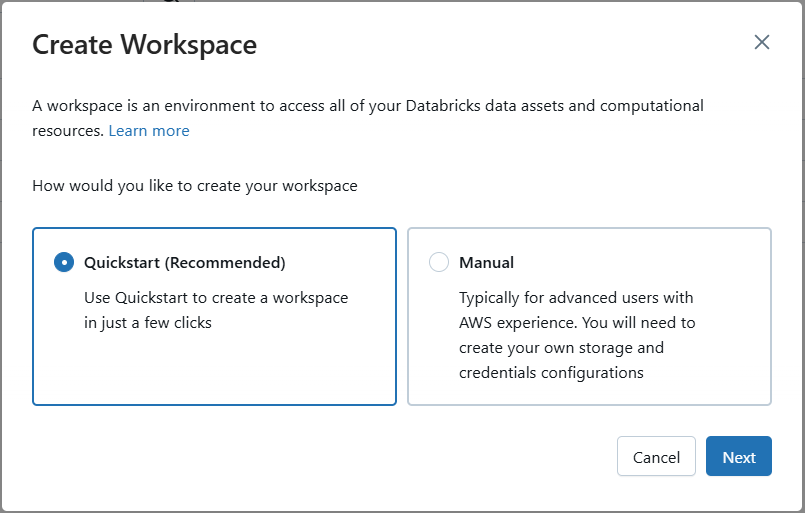
When asked to create cloud resources, follow your organization’s best practices. The “Add Automatically” option is the quickest way to get started, if permissible. Select “Log In to AWS and create workspace” and follow the prompts to begin workspace initialization. This can take up to 10 minutes to complete.
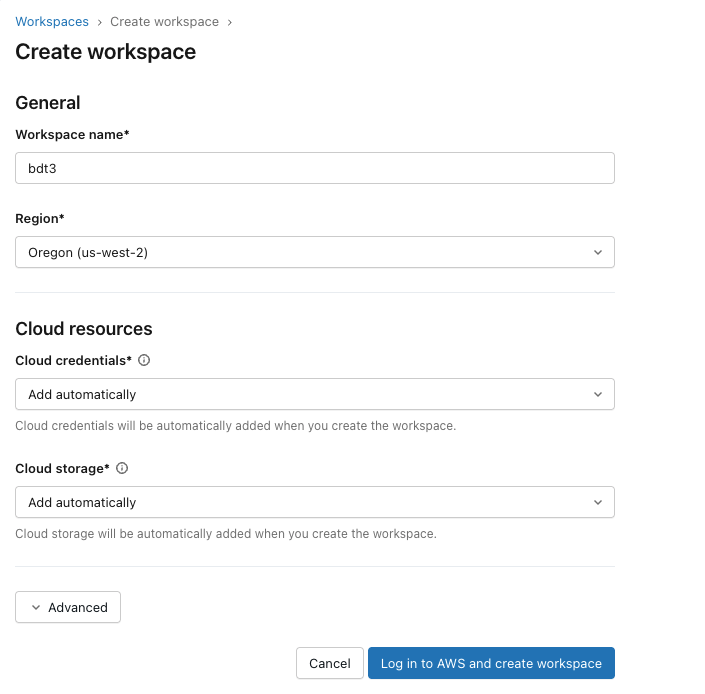
Launch the workspace once it has been created successfully.
Add Notebook to Databricks Workspace#
Create a Databricks Cluster#
The Databricks Runtime of the cluster depends on the version of BDT3.
For BDT3 Version 3.0: DBR 10.4 LTS
For BDT3 Version 3.1: DBR 11.x
For BDT3 Version 3.2: DBR 12.2 LTS, DBR 13.3 LTS
For BDT3 Version 3.3: DBR 14.3 LTS
For BDT3 Version 3.4: DBR 14.3 LTS
For BDT3 Version 3.5: DBR 16.4 LTS
Currently, Shared access mode is not supported. A policy must be selected that does not force shared access mode. See the table of Databricks policies and access modes supported by BDT on the System Requirements page for more details.
Install Big Data Toolkit#
The BDT jar and whl files can be installed either from the Databricks Workspace or from S3 Storage.
Upload the jar and whl files to the databricks workspace or to a location in S3
Go to Cluster Libraries and install the jar and whl from their location in the Workspace or S3 storage
If the Workspace is enabled for Unity Catalog the BDT jar must be installed from a Volume
Upload the jar to a location in S3 and create an external location in the Unity Catalog and assign users read permissions.
Register the external location as a Volume in the Unity Catalog
In the Catalog tab navigate through the Volume and copy the path to the BDT jar
Go to Cluster Libraries and install the jar from the Volume path
We recommend installing the BDT whl from the Volume as well but Databricks also allows python libraries from the Workspace
It is also recommended to install GeoPandas and its supporting libraries to visualize results in notebooks. Use PyPi in the cluster library installation window to install the following libraries:
geopandas
folium
matplotlib
mapclassify
* pyarrow is also required for GeoPandas visualization but is already pre-installed in databricks
Connect Cluster to Amazon S3 Storage#
This guide provides instructions on connecting to AWS S3 from Databricks using an instance profile. Connecting to S3 using an instance profile is required to use BDT’s Geoenrichment and Network Analysis functionalities.
Once the instance profile has been configured, return to the cluster settings. Above the Advanced Options section, set the Instance Profile to the profile that has just been created.
