Processor Erase#
Table of Contents
Part 0: Setup BDT#
[ ]:
import bdt
bdt.auth("bdt.lic")
from bdt.processors import *
from bdt.functions import *
from pyspark.sql.functions import *
BDT has been successfully authorized!
Welcome to
___ _ ___ __ ______ __ __ _ __
/ _ ) (_) ___ _ / _ \ ___ _ / /_ ___ _ /_ __/ ___ ___ / / / /__ (_) / /_
/ _ | / / / _ `/ / // // _ `// __// _ `/ / / / _ \/ _ \ / / / '_/ / / / __/
/____/ /_/ \_, / /____/ \_,_/ \__/ \_,_/ /_/ \___/\___//_/ /_/\_\ /_/ \__/
/___/
BDT python version: v3.5.0-v3.5.0
BDT jar version: v3.5.0-v3.5.0
Part 1: Generate Sample Data#
The below code generates sample data that looks like the following image:
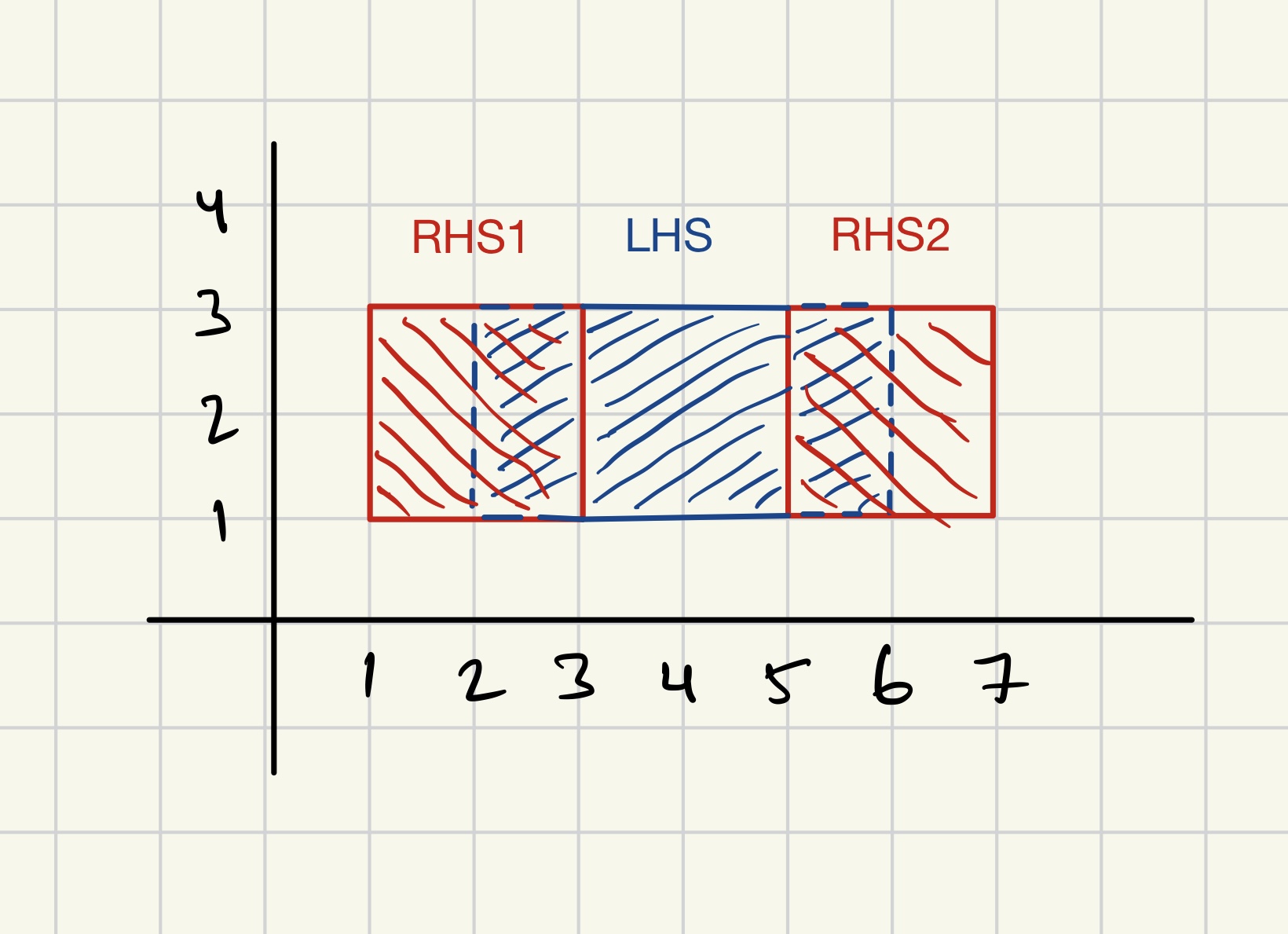
In the above image, the RHS1 polygon overlaps the LHS polygon on the left, and the RHS2 polygon overlaps the LHS polygon on the right. The overlapping areas will be erased from the LHS polygon using Processor Erase.
[ ]:
lhs_wkt = "POLYGON ((2 1, 6 1, 6 3, 2 3, 2 1))"
lhs_df = (spark
.createDataFrame([(lhs_wkt,)], schema="wkt string")
.select(st_fromText("wkt").alias("SHAPE"))
.withMeta("polygon", 4326))
(
lhs_df
.select(st_asText("SHAPE").alias("WKT"))
.show(truncate=False)
)
rhs_wkt1 = "POLYGON ((1 1, 3 1, 3 3, 1 3, 1 1))"
rhs_wkt2 = "POLYGON ((5 1, 7 1, 7 3, 5 3, 5 1))"
rhs_df = (
spark.createDataFrame([
(rhs_wkt1,),
(rhs_wkt2,)], schema="wkt string")
.select(st_fromText("wkt").alias("SHAPE"))
.withMeta("polygon", 4326))
(
rhs_df
.select(st_asText("SHAPE").alias("WKT"))
.show(truncate=False)
)
+------------------------------------------+
|WKT |
+------------------------------------------+
|MULTIPOLYGON (((2 1, 6 1, 6 3, 2 3, 2 1)))|
+------------------------------------------+
+------------------------------------------+
|WKT |
+------------------------------------------+
|MULTIPOLYGON (((1 1, 3 1, 3 3, 1 3, 1 1)))|
|MULTIPOLYGON (((5 1, 7 1, 7 3, 5 3, 5 1)))|
+------------------------------------------+
Part 2: Processor Erase#
Processor Erase will erase the overlapping area (take the difference) of each lhs polygon with all of its overlapping rhs polygons.
The “mode” parameter controls how the overlapping areas are erased, and is an optimization parameter. Changing this parameter will not change the output of the processor.
[ ]:
result_df = erase(
lhs_df,
rhs_df,
cell_size = 4.0,
mode = "union",
do_broadcast = False,
lhs_shape_field = "SHAPE",
rhs_shape_field = "SHAPE",
acceleration = "none",
extent_list = [-180.0, -90.0, 180.0, 90.0],
depth = 16)
(
result_df
.select(st_asText("SHAPE").alias("WKT"))
.show(truncate=False)
)
+------------------------------------------+
|WKT |
+------------------------------------------+
|MULTIPOLYGON (((3 1, 5 1, 5 3, 3 3, 3 1)))|
+------------------------------------------+
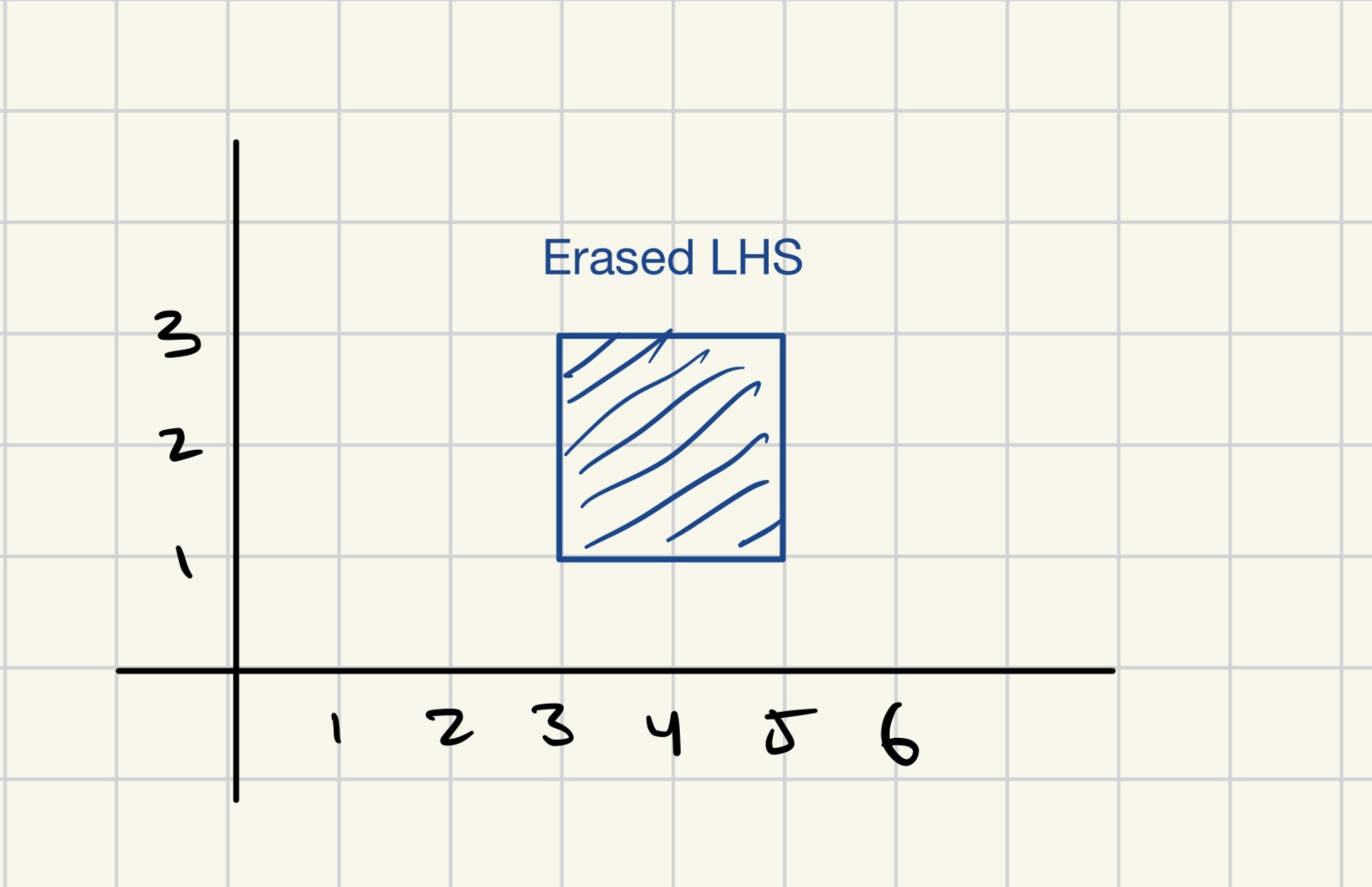
Area on the both the left and right side of the LHS polygon has been erased.