Point in Polygon: SQL#
Table of Contents#
[ ]:
import bdt
bdt.auth("bdt.lic")
from bdt import functions as B
from pyspark.sql.functions import lit, explode
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
Part 1: Generate Sample Data#
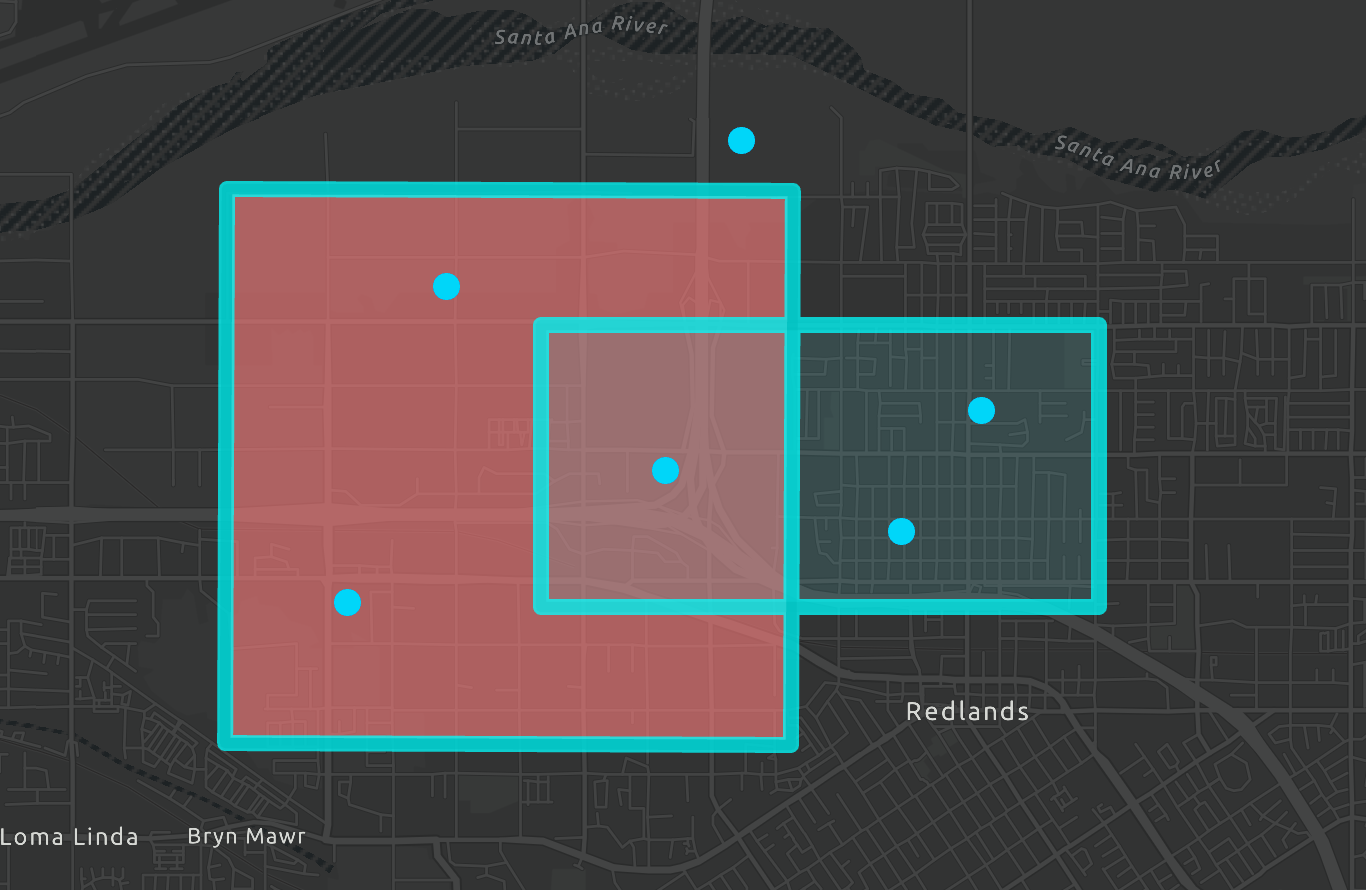
Both the Polygon and Point Dataframes are created from scratch by specifying the data and schema
A unique identifier and the associated WKT value are added to each row
Create the Polygon Data#
[ ]:
polygon1 = """POLYGON ((-117.17 34.08,
-117.17 34.06,
-117.21 34.06,
-117.21 34.08))"""
polygon2 = """POLYGON ((-117.23 34.09,
-117.19 34.08,
-117.19 34.05,
-117.23 34.05))"""
polySchema = StructType([StructField("POLY_ID", IntegerType()),
StructField("POLY_WKT",StringType())])
polyData = [(1, polygon1),
(2, polygon2)]
polyDF = spark.createDataFrame(data = polyData, schema = polySchema)
polyDF.show(truncate = False)
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------+
|POLY_ID|POLY_WKT |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------+
|1 |POLYGON ((-117.17 34.08, \n -117.17 34.06,\n -117.21 34.06,\n -117.21 34.08))|
|2 |POLYGON ((-117.23 34.09,\n -117.19 34.08,\n -117.19 34.05,\n -117.23 34.05)) |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------+
Create the Point Data#
[ ]:
point1 = "POINT (-117.21 34.08)"
point2 = "POINT (-117.22 34.06)"
point3 = "POINT (-117.20 34.07)"
point4 = "POINT (-117.18 34.07)"
point5 = "POINT (-117.18 34.07)"
point6 = "POINT (-117.20 34.09)"
pointSchema = StructType([StructField("POINT_ID", IntegerType()),
StructField("POINT_WKT",StringType())])
pointData = [(1, point1),
(2, point2),
(3, point3),
(4, point4),
(5, point5),
(6, point6)]
pointDF = spark.createDataFrame(data = pointData, schema = pointSchema)
pointDF.show(truncate = False)
+--------+---------------------+
|POINT_ID|POINT_WKT |
+--------+---------------------+
|1 |POINT (-117.21 34.08)|
|2 |POINT (-117.22 34.06)|
|3 |POINT (-117.20 34.07)|
|4 |POINT (-117.18 34.07)|
|5 |POINT (-117.18 34.07)|
|6 |POINT (-117.20 34.09)|
+--------+---------------------+
Part 2: Point in Polygon#
Create SHAPE structs in each DataFrame#
st_FromText converts a WKT representation of a geometry to BDT’s internal Shape Struct object. The default convention is to label this Shape Struct as ‘SHAPE’.
[ ]:
polyDF_S = polyDF.select("*", B.st_fromText("POLY_WKT").alias("SHAPE"))
polyDF_S.show()
[ ]:
pointDF_S = pointDF.select("*", B.st_fromText("POINT_WKT").alias("SHAPE"))
pointDF_S.show(3)
Add QR Values to each DataFrame#
QR is Big Data Toolkit’s internal spatial partitioning mechanism
cellSize determines the QR value(s) assigned to a given geometry
[ ]:
cellSize = 5.0
Generate QR values for each SHAPE struct using st_asQR
The spark sql function ‘explode’ takes the resulting QR list and gives each QR in the list its own unique row. This should always be used with st_asQR
[ ]:
pointDF_S_QR = pointDF_S\
.select("*", explode(B.st_asQR("SHAPE", lit(cellSize))).alias("QR"))\
.repartition("QR")
pointDF_S_QR.show(3)
pointDF_S_QR.createOrReplaceTempView("pointDF_S_QR")
[ ]:
polygonDF_S_QR = polyDF_S\
.select("*", explode(B.st_asQR("SHAPE", lit(cellSize))).alias("QR"))\
.repartition("QR")
polygonDF_S_QR.show(5)
polygonDF_S_QR.createOrReplaceTempView("polyDF_S_QR")
Point in Polygon Using SQL (ST_Contains with QR values)#
Point in Polygon can be done entirely in SQL
Inner Join the point and polygon DataFrames on QR with the condition that the polygon contains the point.
[ ]:
pipped = sql("""
SELECT POINT_ID, POINT_WKT, pointDF_S_QR.SHAPE, POLY_ID, POLY_WKT
FROM pointDF_S_QR INNER JOIN polyDF_S_QR
ON pointDF_S_QR.QR = polyDF_S_QR.QR
AND ST_Contains(polyDF_S_QR.SHAPE, pointDF_S_QR.SHAPE, 4326)
""")
print(pipped.count())
pipped.show(3)
6
+--------+--------------------+--------------------+-------+--------------------+
|POINT_ID| POINT_WKT| SHAPE|POLY_ID| POLY_WKT|
+--------+--------------------+--------------------+-------+--------------------+
| 1|POINT (-117.21 34...|{[01 01 00 00 00 ...| 2|POLYGON ((-117.23...|
| 2|POINT (-117.22 34...|{[01 01 00 00 00 ...| 2|POLYGON ((-117.23...|
| 3|POINT (-117.20 34...|{[01 01 00 00 00 ...| 1|POLYGON ((-117.17...|
+--------+--------------------+--------------------+-------+--------------------+
only showing top 3 rows