Setup for Network Analysis in Azure Databricks#
The BDT Network Analysis Functions require an additional, seperate license for the LMDB. Please contact the BDT team at bdt_support@esri.com if interested. This guide describes how to enable a cluster with this data.
Prerequisites#
This guide assumes BDT is already installed and set up in an environment of choice. If this is not done see the setup guide for more information.
For best performance, it is recommended to use a cluster with at least 128GB of memory. It is also recommended to use a cluster with many smaller machines (fewer cores) rather than a few large machines.
Please be sure to obtain the file containing the LMDB from the BDT team.
This file should be stored in Azure Blob Storage.
Download the init script and edit the name and contents to match the version, year and quarter of the LMDB provided.
1. Setup Init Script#
Generate a SAS token for the Azure Storage Account with all sevices, resource types, and permissions allowed. Save the token in a secure location. For more information on how to do this see: create a SAS token for your storage account
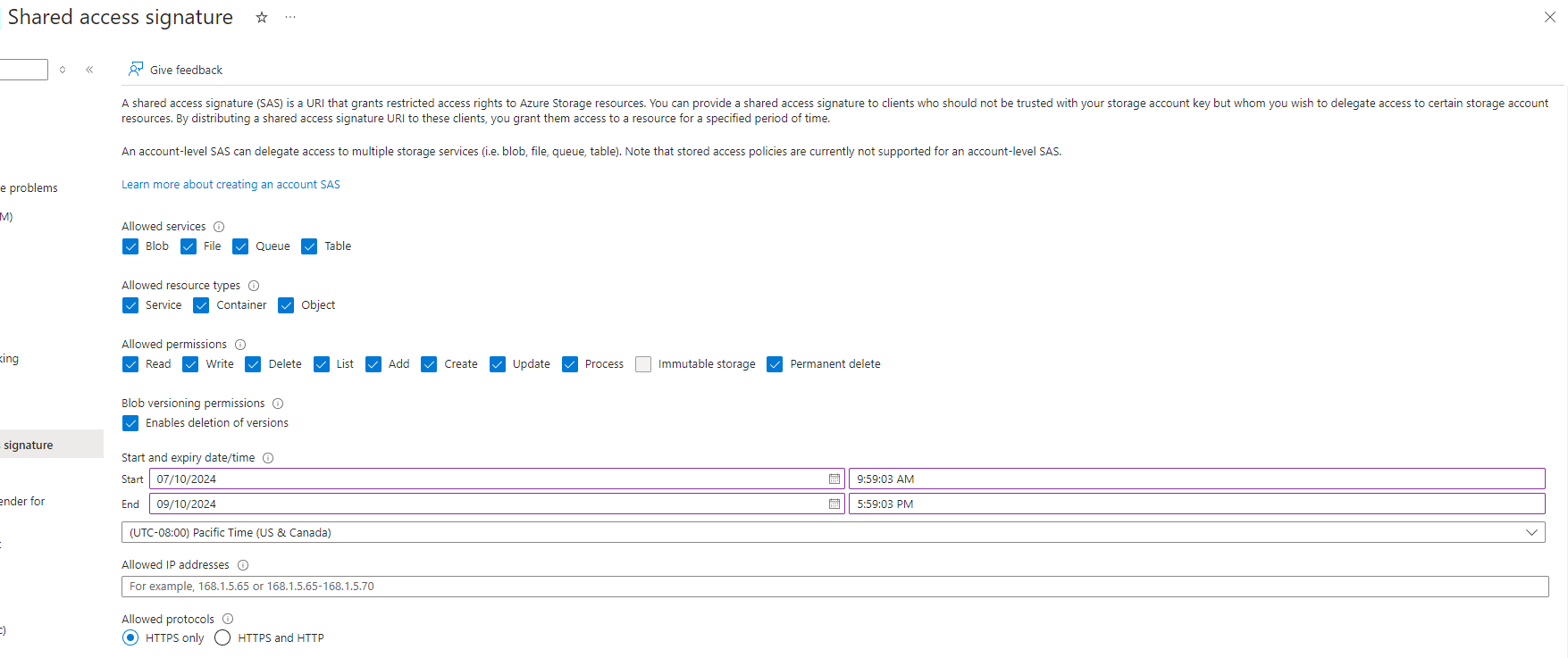
Open the Init Script in a text editor. Add the path to the LMDB in Azure Blob Storage and the SAS token to this line:
azcopy copy '<path>/<to>/<LMDB>/?<SAS token>' '/data' --recursive=true
2. Upload the Script to the Databricks workspace#
In the Databricks Workspace, Click on Workspace in the left-hand menu.
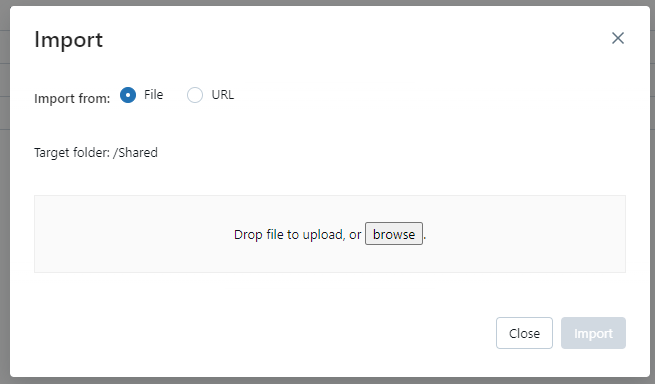
Click on the three dots in the upper right corner, then click Import.
Drag-and-drop the init script that was just downloaded into the popup window, then click Import.
3. Add Script to Cluster#
In Cluster Creation or Editing, under Advanced Options Click on the Init Scripts tab
Make sure the source is set to Workspace (this is the default). Then click on the folder icon.
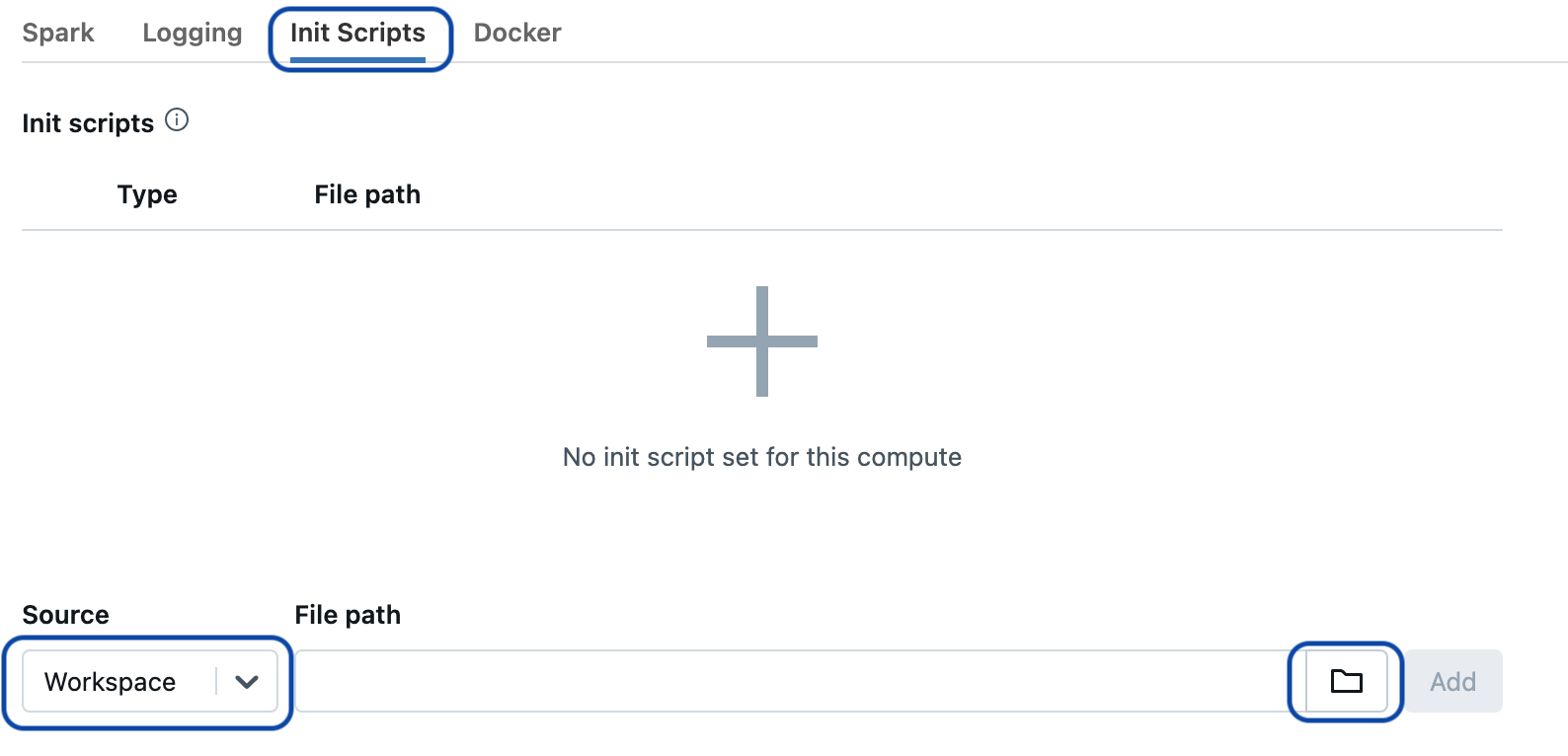
Browse to the init script that was just uploaded, select the script, then click Add.
4. Add Spark Properties#
Click on the Spark tab of advanced options.
Add the following properties to the Spark Config section, after updating with the version, year and quarter of the LMDB provided:
spark.bdt.lmdb.path /local_disk0/data/LMDB_<version>_<year>_<quarter>
spark.bdt.lmdb.map.size 304857600000
Click Confirm to save the changes.
5. Start the Cluster#
Click Start to restart the cluster.
Once the cluster has been started, verify that the LMDB has been added by running the following in a notebook:
from bdt.functions import st_fromText, st_drive_time
df = (spark
.createDataFrame([("POINT (-13161875 4035019.53758)",)], ["WKT"])
.select(st_fromText(col("WKT")).alias("SHAPE")))
out_df = (df
.select(st_drive_time("SHAPE", 30, 125.0).alias("DT"))
.selectExpr("inline(DT)"))
out_df.show()