Route Closest Target#
Processor RouteClosestTarget requires an additional, separate license for street map premium data. Please contact the BDT team at bdt_support@esri.com if you are interested.
Table of Contents
Part 0: Setup BDT#
[ ]:
import bdt
bdt.auth("bdt.lic")
from bdt.processors import *
from pyspark.sql.types import StructType, StructField, DoubleType
BDT has been successfully authorized!
Welcome to
___ _ ___ __ ______ __ __ _ __
/ _ ) (_) ___ _ / _ \ ___ _ / /_ ___ _ /_ __/ ___ ___ / / / /__ (_) / /_
/ _ | / / / _ `/ / // // _ `// __// _ `/ / / / _ \/ _ \ / / / '_/ / / / __/
/____/ /_/ \_, / /____/ \_,_/ \__/ \_,_/ /_/ \___/\___//_/ /_/\_\ /_/ \__/
/___/
BDT python version: v3.5.0-v3.5.0
BDT jar version: v3.5.0-v3.5.0
Part 1: What is Route Closest Target?#
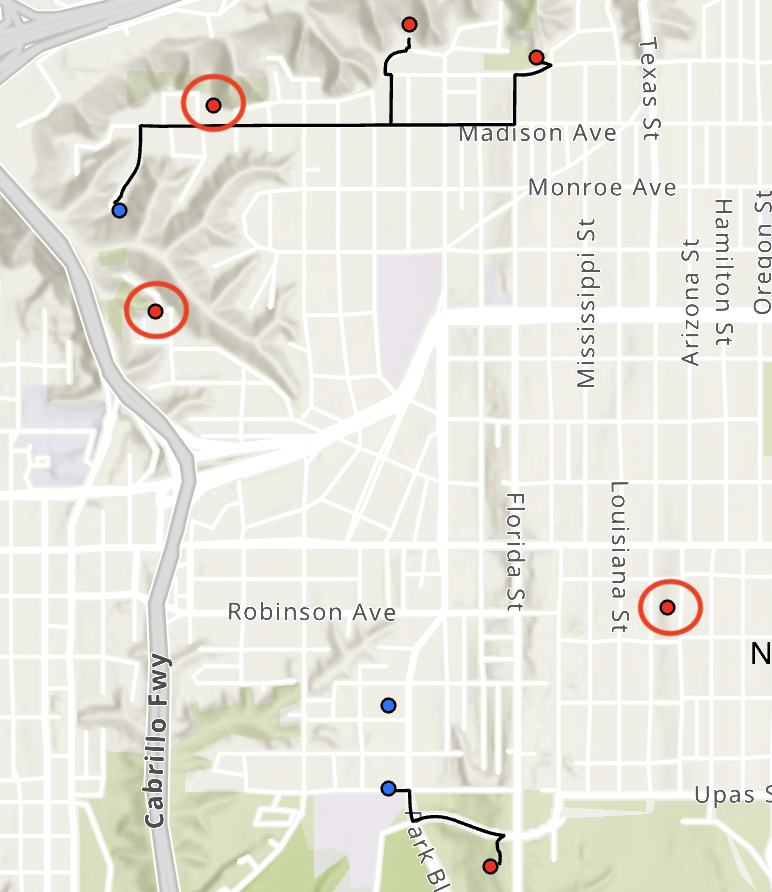
Route Closest Target will find the closest target (destination) point from each origin point using the road network.
From here on, target (destination) points will be represented as blue, and origin points as red.
The below image is an image of the sample data used in this notebook.
Route Closest Target was originally designed to solve network adequacy problems. Network adequacy is requirement in the healthcare industry that stipulates all members must have access to a hospital or provider within a set time or distance.
Part 2: Route Closest Target#
Generate Sample Data#
Two DataFrames are created, one of origin points and one of target (destination) points. In the case of healthcare network adequacy, these can be thought of as member points and provider points.
[ ]:
origin_schema = StructType([StructField("OX", DoubleType()),
StructField("OY", DoubleType())])
origin_points = [(-13040800.98123, 3864013.475744),
(-13040484.574291, 3860694.049651),
(-13040302.581114, 3863882.764771),
(-13039786.093915, 3861714.605291),
(-13041802.162892, 3862881.33078),
(-13041576.09564, 3863696.259199)]
origin_df = spark.createDataFrame(data = origin_points, schema = origin_schema)
dest_schema = StructType([StructField("DX", DoubleType()),
StructField("DY", DoubleType())])
origin_df.show(6)
dest_points = [(-13040884.714752, 3861002.234746),
(-13041944.162426, 3863283.200951),
(-13040883.863412, 3861330.721683)]
dest_df = spark.createDataFrame(data = dest_points, schema = dest_schema)
dest_df.show(5)
+------------------+--------------+
| OX| OY|
+------------------+--------------+
| -1.304080098123E7|3864013.475744|
|-1.3040484574291E7|3860694.049651|
|-1.3040302581114E7|3863882.764771|
|-1.3039786093915E7|3861714.605291|
|-1.3041802162892E7| 3862881.33078|
| -1.304157609564E7|3863696.259199|
+------------------+--------------+
+------------------+--------------+
| DX| DY|
+------------------+--------------+
|-1.3040884714752E7|3861002.234746|
|-1.3041944162426E7|3863283.200951|
|-1.3040883863412E7|3861330.721683|
+------------------+--------------+
Run ProcessorRouteClosestTarget#
RouteClosestTarget takes max minutes and max meters as processor parameters. If a target (destination) point is not found within the max minutes or max meters threshold, then search is stopped and null is emitted.
Below, RouteClosestTarget is run on the sample data created above with max minutes set to 20 and max meters set to 20,000 (about 15 miles). Everything in the example falls within these thresholds, and therefore will be routed.
[ ]:
max_minutes = 20
max_meters = 20_000
out_df = routeClosestTarget(
origin_df,
dest_df,
maxMinutes=max_minutes,
maxMeters=max_meters,
oxField="OX",
oyField="OY",
dxField="DX",
dyField="DY",
origTolerance=500,
destTolerance=500,
costOnly=False)
out_df.show(10)
+------------------+--------------+------------------+--------------+------------------+------------------+--------------------+
| OX| OY| DX| DY| TIME| DIST| SHAPE|
+------------------+--------------+------------------+--------------+------------------+------------------+--------------------+
|-1.3041802162892E7| 3862881.33078|-1.3040883863412E7|3861330.721683| 6.240910940463221|2582.5853657599773|{[01 05 00 00 00 ...|
| -1.304157609564E7|3863696.259199|-1.3041944162426E7|3863283.200951| 2.911609765894674| 701.2172205408888|{[01 05 00 00 00 ...|
| -1.304080098123E7|3864013.475744|-1.3041944162426E7|3863283.200951| 6.27362991|1862.9740681539006|{[01 05 00 00 00 ...|
|-1.3040484574291E7|3860694.049651|-1.3040884714752E7|3861002.234746|1.5536894827098346| 796.6896446460836|{[01 05 00 00 00 ...|
|-1.3040302581114E7|3863882.764771|-1.3041944162426E7|3863283.200951| 5.434412286454162|2108.1517904015905|{[01 05 00 00 00 ...|
|-1.3039786093915E7|3861714.605291|-1.3040884714752E7|3861002.234746|3.6686477418818675|2138.9312933853053|{[01 05 00 00 00 ...|
+------------------+--------------+------------------+--------------+------------------+------------------+--------------------+
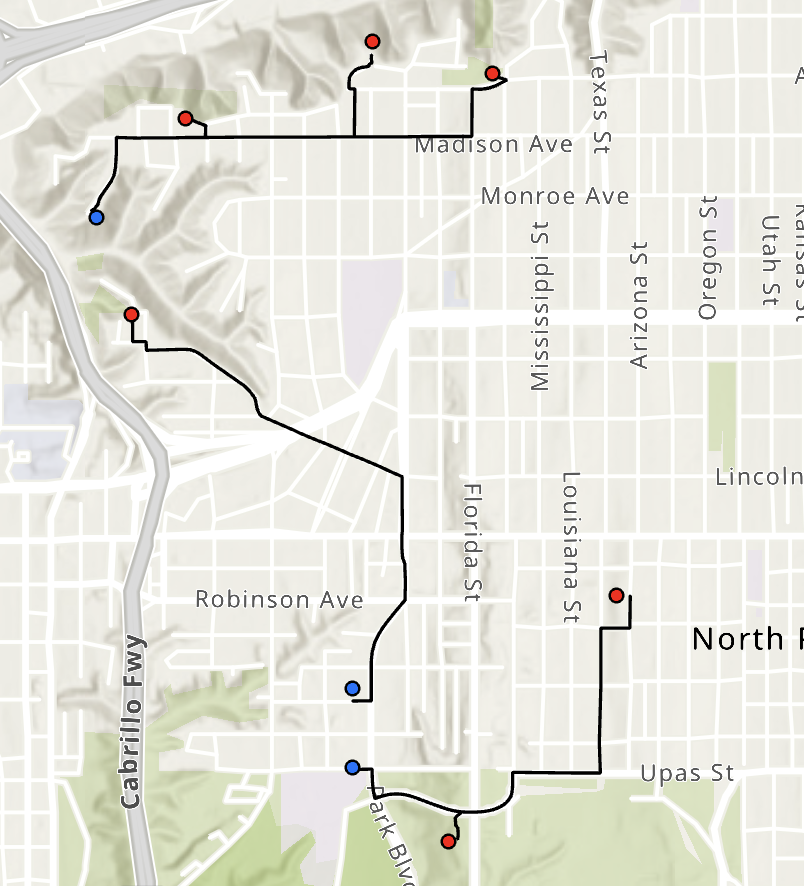
The below image shows each origin point routed to its closest target (destination) using ProcessorRouteClosestTarget.
Part 3: Route Closest Target 2#
RouteClosestTarget2 does the same thing as RouteClosestTarget, but instead of max time and max meters being parameters to the processor, they are required as columns in the input origin DataFrame. This allows for the max time and max meters criterion to be dynamic per row.
Generate Sample Data#
Again, two DataFrames are created, one of origin points and one of target (destination) points. The points are the same as the Route Closest Target example, but there are now two new columns in the origin DataFrame: MaxMins and MaxMeters.
[ ]:
origin_schema = StructType([StructField("OX", DoubleType()),
StructField("OY", DoubleType()),
StructField("MaxMins", DoubleType()),
StructField("MaxMeters", DoubleType())])
origin_points = [(-13040800.98123, 3864013.475744, 20.0, 15.0),
(-13040484.574291, 3860694.049651, 20.0, 15.0),
(-13040302.581114, 3863882.764771, 20.0, 15.0),
(-13039786.093915, 3861714.605291, 2.0, 0.2),
(-13041802.162892, 3862881.33078, 2.0, 0.2),
(-13041576.09564, 3863696.259199, 2.0, 0.2)]
origin_df = spark.createDataFrame(data = origin_points, schema = origin_schema)
origin_df.show(6)
dest_schema = StructType([StructField("DX", DoubleType()),
StructField("DY", DoubleType())])
dest_points = [(-13040884.714752, 3861002.234746),
(-13041944.162426, 3863283.200951),
(-13040883.863412, 3861330.721683)]
dest_df = spark.createDataFrame(data = dest_points, schema = dest_schema)
dest_df.show(3)
+------------------+--------------+-------+---------+
| OX| OY|MaxMins|MaxMeters|
+------------------+--------------+-------+---------+
| -1.304080098123E7|3864013.475744| 20.0| 15.0|
|-1.3040484574291E7|3860694.049651| 20.0| 15.0|
|-1.3040302581114E7|3863882.764771| 20.0| 15.0|
|-1.3039786093915E7|3861714.605291| 2.0| 0.2|
|-1.3041802162892E7| 3862881.33078| 2.0| 0.2|
| -1.304157609564E7|3863696.259199| 2.0| 0.2|
+------------------+--------------+-------+---------+
+------------------+--------------+
| DX| DY|
+------------------+--------------+
|-1.3040884714752E7|3861002.234746|
|-1.3041944162426E7|3863283.200951|
|-1.3040883863412E7|3861330.721683|
+------------------+--------------+
Run ProcessorRouteClosestTarget2#
RouteClosestTarget2 does not take max minutes nor max meters as processor parameters. Instead, it gets those values from the input origin DataFrame as mentioned above.
[ ]:
out_df = routeClosestTarget2(
origin_df,
dest_df,
maxMinutesField = "MaxMins",
maxMetersField = "MaxMeters",
oxField="OX",
oyField="OY",
dxField="DX",
dyField="DY",
origTolerance=500,
destTolerance=500,
costOnly=False)
out_df.drop("DX", "DY").show(10)
+------------------+--------------+-------+---------+------------------+------------------+--------------------+
| OX| OY|MaxMins|MaxMeters| TIME| DIST| SHAPE|
+------------------+--------------+-------+---------+------------------+------------------+--------------------+
|-1.3041802162892E7| 3862881.33078| 2.0| 0.2| NULL| NULL| NULL|
| -1.304157609564E7|3863696.259199| 2.0| 0.2| NULL| NULL| NULL|
|-1.3040302581114E7|3863882.764771| 20.0| 15.0| 5.434412286454162|2108.1517904015905|{[01 05 00 00 00 ...|
|-1.3039786093915E7|3861714.605291| 2.0| 0.2| NULL| NULL| NULL|
| -1.304080098123E7|3864013.475744| 20.0| 15.0| 6.27362991|1862.9740681539006|{[01 05 00 00 00 ...|
|-1.3040484574291E7|3860694.049651| 20.0| 15.0|1.5536894827098346| 796.6896446460836|{[01 05 00 00 00 ...|
+------------------+--------------+-------+---------+------------------+------------------+--------------------+
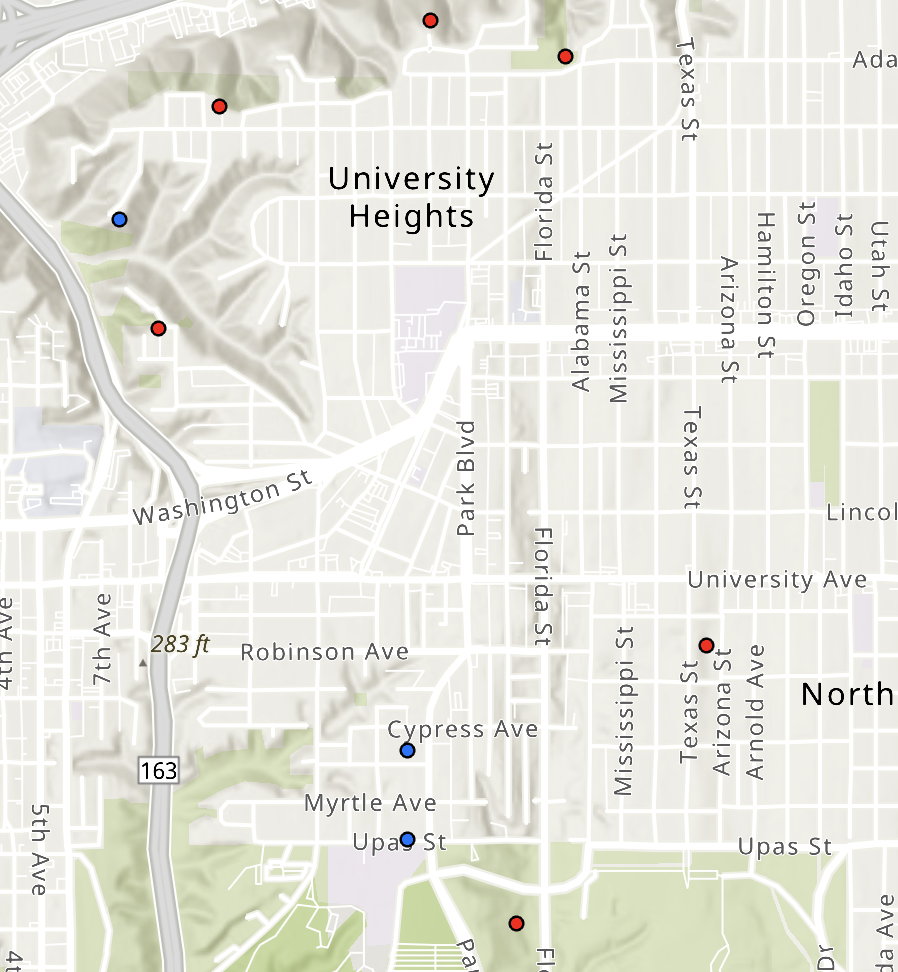
The below image shows some (not all) origin points routed to their closest target (destination) using ProcessorRouteClosestTarget2.
Some origin points (circled in red) do not find a destination point . That is because the max minutes and max meters values are 2 and 0.2 for some rows in the input DataFrame, and the closest destination point is beyond those max values.