Processor Stay#
Table of Contents
Part 0: Setup BDT#
[ ]:
import bdt
bdt.auth("bdt.lic")
from bdt.processors import *
from bdt.functions import *
from pyspark.sql.functions import *
BDT has been successfully authorized!
Welcome to
___ _ ___ __ ______ __ __ _ __
/ _ ) (_) ___ _ / _ \ ___ _ / /_ ___ _ /_ __/ ___ ___ / / / /__ (_) / /_
/ _ | / / / _ `/ / // // _ `// __// _ `/ / / / _ \/ _ \ / / / '_/ / / / __/
/____/ /_/ \_, / /____/ \_,_/ \__/ \_,_/ /_/ \___/\___//_/ /_/\_\ /_/ \__/
/___/
BDT python version: v3.5.0-v3.5.0
BDT jar version: v3.5.0-v3.5.0
Part 1: What Is Processor Stay#
Processor stay detection sifts through sequential GPS “breadcrumb” data (a track) to pinpoint areas (stays also known as dwells) where devices have little or no movement over a certain period of time.
A track is an time-ordered sequence of points. For example, the path a person takes to work.
A stay is a sub-sequence of points in the track that are clustered together in time and space. For example, if you are walking around your house (moving, but staying in a confined area).
The algorithm used is greedy and implements a “look-forward” approach. The below illustrations show how it works.
The algorithm has two threshold parameters to determine proxmity in time and space:
A distanceThreshold to find nearby points.
A timeThreshold to check if the total time elapsed is greater than the minimum duration. If yes then it is considered a stay.
For the below example:
distanceThreshold = 2 meters
timeThreshold = 2 seconds
Points that are <= distanceThreshold from the stay start point are considered dwelled together. If the difference in time between the first and last points in the stay is greater than the timeThreshold, the stay is emitted.
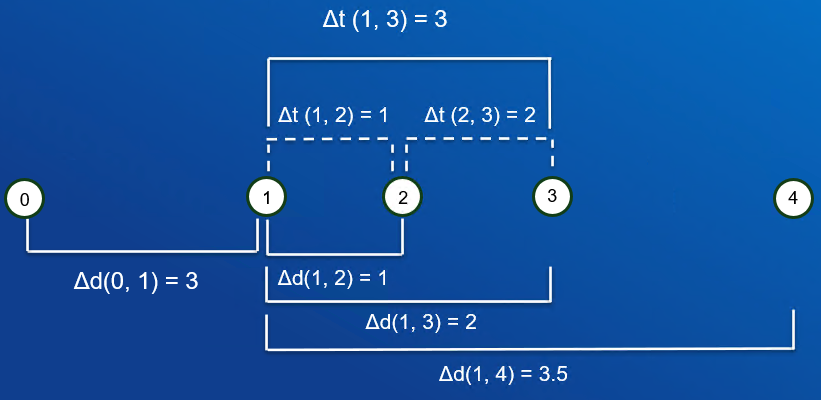
First, point 0 is ignored since the distance from point 0 to point 1 is greater than the distance threshold. Point 1 is now the start of the next potential stay.
Points 1 and 2 are dwelled together because the distance between points 1 and 2 is within the distance threshold.
Next, point 3 is dwelled together with points 1 and 2 because the distance between points 1 and 3 is within the distance threshold.
Finally, point 4 is not dwelled together with points 1, 2 and 3 because the distance between points 1 and 4 exceeds the distance threshold. Points 1, 2, and 3 are emitted as a stay because the difference in time between points 1 and 3 is greater than the time threshold.
Part 2: Using Processor Stay#
First, sample data is generated to replicate the example above.
[ ]:
df = (spark.createDataFrame([
(1, 0.0, 0.0, 0, 0),
(1, 3.0, 0.0, 1, 1),
(1, 4.0, 0.0, 2, 2),
(1, 5.0, 0.0, 4, 3),
(1, 6.5, 0.0, 5, 4),], schema="trackid long, x double, y double, timestamp long, id int"))
df.show()
+-------+---+---+---------+---+
|trackid| x| y|timestamp| id|
+-------+---+---+---------+---+
| 1|0.0|0.0| 0| 0|
| 1|3.0|0.0| 1| 1|
| 1|4.0|0.0| 2| 2|
| 1|5.0|0.0| 4| 3|
| 1|6.5|0.0| 5| 4|
+-------+---+---+---------+---+
Calling processor stay is relatively straightforward. Refer to the api documentation for more details.
[ ]:
result_df = df.stay(track_id_field="trackid",
time_field="timestamp",
center_type="standard",
dist_threshold=2,
time_threshold=2,
x_field="x",
y_field="y",
wkid=3857)
The ouput schema looks like below:
[ ]:
result_df.printSchema()
root
|-- trackid: long (nullable = true)
|-- STAY_CENTER_X: double (nullable = false)
|-- STAY_CENTER_Y: double (nullable = false)
|-- N: integer (nullable = false)
|-- STAY_START_TIME: long (nullable = false)
|-- STAY_END_TIME: long (nullable = false)
|-- STAY_DURATION: long (nullable = false)
N represents the number of points in the stay.
The centroid of the stay can either be “standard” or “time-weighted”. The standard centroid is the spatial average of all the points in the stay. The time-weighted centroid is the time-weighted spatial average of all the points in the stay. Each point is weighted by the time between it and the next point.
[ ]:
result_df.show(truncate=False)
+-------+-------------+-------------+---+---------------+-------------+-------------+
|trackid|STAY_CENTER_X|STAY_CENTER_Y|N |STAY_START_TIME|STAY_END_TIME|STAY_DURATION|
+-------+-------------+-------------+---+---------------+-------------+-------------+
|1 |4.0 |0.0 |3 |1 |4 |3 |
+-------+-------------+-------------+---+---------------+-------------+-------------+
One stay for the output having 3 points.